









We’re employee-owned, every team member you work with brings the mindset of a business owner.

Alan Coleman, CEO






Wolfgang Digital is an equal opportunity employer committed to fostering an inclusive workplace



Wolfgang Digital is an equal opportunity employer committed to fostering an inclusive workplace


One of the more complex and perhaps least commonly-understood issues we’ve faced here on the Wolfgang Digital SEO team over the past 12 months has been the rise in prominence, frequency and general havoc incurred at the hands of the dreaded ‘spider trap’, or ‘crawler trap’ as they’re sometimes referred to.
A spider trap is something webmasters should strive to avoid at all costs, as its essentially a death knoll to your site’s ability to be crawled and indexed, which in turn impacts negatively on overall organic visibility, rankings and ultimately, your site’s ability to generate revenue; it’s kind of a big deal when contextualised as such!
So, in order to ensure you have a solid understanding of the potential impact of a spider trap, it’s important that we give an overview of what a spider trap is, how to identify one and how to diagnose one, but before we weave that particular web (pardon the spidery pun!), let’s take a step back and understand the fundamental reason why any of this is important to us as website optimisers, business owners and marketers; it’s all down to the concept of crawl budget and how you can influence website performance in the context of maintaining crawl efficiency through effective URL management.
Google and the other search engines have invested significant capital in creating these wonderful search engines that have become ingrained in our day-to-day lives; gone are the days when we dusted off an old Encyclopaedia Britannica for authoritative answers to our daily queries or the innocent early-internet days of simply ‘Asking Jeeves’ and hoping he served us up a treat! Search engines are big business, and with SEO spend set to skyrocket to $80bn in the US alone by 2020, chances are, they’re here to stay, in one form or another.
With the ever-evolving Google algorithm at the forefront of evrything we in the SEO industry try to build our best practices around, it’s fair to assume that there’s a significant cost associated with Big G maintaining this vast, Rankbrain-driven beast. Needless to say, the bots/crawlers/spiders employed by Lord Googlebot to crawl our sites, index our content and ultimately, display them to our target audiences, cost money to run. Hosted within vast server networks dotted throughout the globe, there is a financial cost associated with physically providing the bandwidth expended by these spiders as they crawl through the web on a continual basis.

Fundamentally, if a website isn’t optimised to allow spider access to its infrastructure in an efficient manner, a spider will inevitably reach a point in time whereby it reaches its allocated bandwidth allowance for a given site and moves on the next website on its crawl schedule, rather than hanging around indefinitely on the same site, hope that it finds a way through a myriad of issues before coming out the other side with a coherent understanding of what it’s just scanned.
Naturally, if there’s been an issue whereby a spider couldn’t complete the task at hand and ceases crawling a site as crawl budget has been reached, then the affected site could in a sense be deemed ‘less than optimal’ in the eyes of the crawler and could in essence be downgraded (when it comes to ranking a site versus, say, a competitor site on which the crawler has no issues accessing) as a result.
Furthermore, if a website has serious crawl issues, then some very important product, category or informational pages may never see the light of day in the SERPs if a spider was unable to reach them to begin with.
To put a slightly weird personification around this concept, consider the following scenario:
You’re walking around a brand new multi-storey shopping centre, browsing through the first couple of shops, deciding which shops you like and might tell your friends about and also which ones you won’t want to visit again.
Then suddenly, just as you’re getting a feel for the place, the shutters come crashing down on the stores, you can’t go any further into this wonderful new shopping complex, the security guards block your path to entry and you have no idea what’s in the remaining shops or how you might spend your budget for the shopping trip you’ve planned.
Naturally, you make a beeline for the nearest exit, perhaps with a sour taste in your mouth, a little less likely to return, and still having no clue what’s beyond the shutters you reached so unexpectedly. You take your hard-earned cash to the neighbouring store, which welcomes you with open arms, meets all your shopping needs and you tell your friends all about how great this place is!
In this scenario (in case I've lost you already!), you are the crawler, the shops are the pages of a website and your friends are the SERPs; can you guess who played the role of the spider trap yet?! Those pesky shutters/security guards of course!
Crawl budget, in its purest definition, can be defined as the number of times a search engine crawler visits your website during a given timeframe, which is heavily influenced by its ease of navigation on a website. For example, if Googlebot typically visits your website approximately X times per month, we can assume with a good degree of confidence that that figure is your monthly crawl budget for Googlebot, although this is by no means set in stone.
It’s important to recognise that estimated crawl budget can evolve over time. Many other factors such as PageRank (the kind that Google still most definitely uses internally despite it being discontinued as a publicly-available toolbar metric) and server host load play a role in crawl budget too, as stated by former friend-to-SEOs, Matt Cutts in a revealing interview on the topic with Eric Enge a couple of years back.
A quick scan of your web logs or indeed via Search Console under ‘Crawl Stats’ will help you gain insight into what your average crawl budget for Google may be at a given point in time.
Here’s an example of what calculating estimated crawl budget looks like for our very own new spanky Wolfgang Digital website:
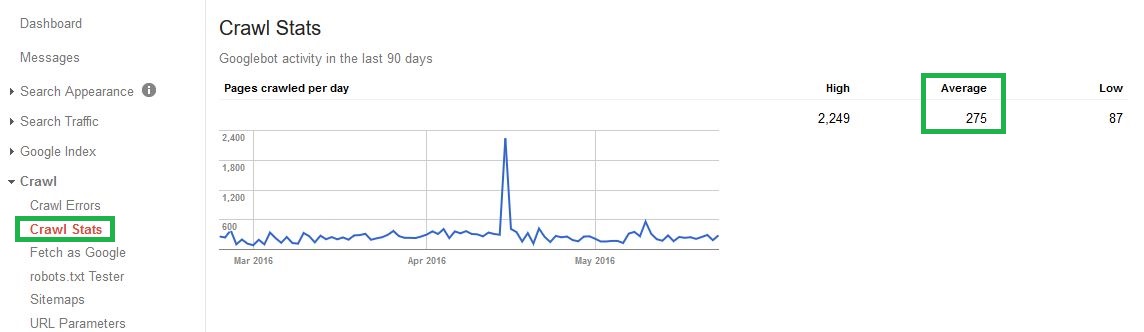
Looking at the above stats, if we take the daily average of 275*30 then we can deduce the average monthly crawl budget for this website from Google is 8250, meaning we now have an estimate of the number of pages we can expect Google to crawl, index and rank within a given timeframe.
If the number of crawlable assets (URLs) we want to rank for is significantly higher (or lower) than this amount, it typically means that we need to look further at crawl budget optimisation as a priority issues from a technical SEO perspective. Thankfully, we’re alright for now, but we regularly encounter scenarios in which websites are struggling with their web IA and oftentimes the root cause can be determined with a simple Screaming Frog crawl, configured to emulate Googlebot.
Bottom line is, if your site can't get indexed, it can't get ranked. Don’t let crawl budget play a part in how a spider treats your site, ensure you’re optimising to allow spiders enter your site, visits what’s important and exit the site left in no uncertain terms that you’ve pulled out all the stops to make it a smooth, logical experience for them.
A spider trap, as bluntly portrayed as an unreasonable security guard or inanimate shutter above, is basically what stands in the way of a spider accessing your website, having a lovely time in there and coming away with nothing but happy memories and some nice indexable pages to rank on SERPs versus the harsh reality of being trapped in a grim, never-ending loop of a section of your site which causes all sorts of trouble and eventually forces them to give up and move on due to pre-programmed bandwidth allowance limits.

Once you have access to the basic tools required in order to perfroma a site crawl, you're ready to commence your crawl analysis to determine whther a spider trap exists on your site.
They’re particularly prevalent on ecommerce sites due to the nature of large inventory management issues and fancy UX-led filtering configurations, but they can be found on pretty much any site with dynamically-served content. Big sites will naturally have more bandwidth allocated to it by search engine spiders, but that doesn’t mean they are less susceptible to being caught in a trap, on the contrary, if fact. Similarly, smaller sites can be equally effected by these issues if they’re not nipped in the bud at an early stage.
Sometimes, a trap is evident at a very early stage, with a loop kicking in with less than half the site crawled.
Here’s an example of a very early stage spider trap on a very small site, where the crawl hits the 8th asset and then loops back through URLs 1-7 before stumbling back over 8 at just 6.4% of crawl completion; this means a staggering 93.6% of this small website is not being crawled, indexed or ranked:

The following crawl completion index illustrates what a mid-stage spider trap looks like, the spiders have crawled a significant chunk of this large site bet can’t get any further, effectively leaving 2/5ths of this large ecommerce site ‘on the shelf’ in terms of potential web visibility:

Other times, it can kick in really late in the day, with almost the entire site crawled, yet the crawl will simply never end due to the crawler continually falling through the infinite loop inflicted by an intricate faceted navigation configuration or a simple coding error.

This can be particularly disheartening as just when you think the crawl is almost complete with only 161 URLs remaining from over 40k, it starts skipping back up around the 200 mark and never falls quite below the 100 mark towards completion.
This kind of trap will likely have less of an impact in the sense that the majority of the site has been crawled, but it’ll undoubtedly cause crawlers to look unfavourably on the site in question and perhaps reduce crawl budget to avoid running through similar issues in future crawls. Best not leave such things to chance in the hope that crawlers deem things ‘OK’ and will index most of what it’s found, we say let’s nip these traps in the bud and make crawl efficiency a non-issue once and for all!
There are four main causes of spider traps which we’ve encountered in recent times, each with varying degrees of complexity to both identify and diagnose; let’s begin with the simpler ones, moving through to the proper headache scenarios for us SEOs (not to mention the poor spiders, who I’m sure by now many of you are visualising as a hairy little Google-critter funnelling its way down the interweb towards your beloved domain!
If you’re more versed in using crawler tools then you may still have some burning questions such as ‘why will this crawl never end?’ or ‘why is smoke emanating from my brand new Lenovo?’; this guide should hopefully put your mind to ease and put you on the path towards an optimal crawler experience for all.
A calendar trap is perhaps the only trap that isn’t the product of a fault or major technical oversight on any dev or webmaster’s part. The pages served are, in theory, legitimate URLs that do serve an ultimate purpose or function; the only issue is that as time, by very definition, is infinite, then so too are any URLs that relate to time!
This is probably the easiest kind of spider trap to understand, spot and address, if you have a calendar on your site that enables a young parent to navigate to and potentially book an event for their newborn baby’s graduation ball, or worse still, a trip to Disneyland in 3016, then it’s likely your site has a calendar trap!
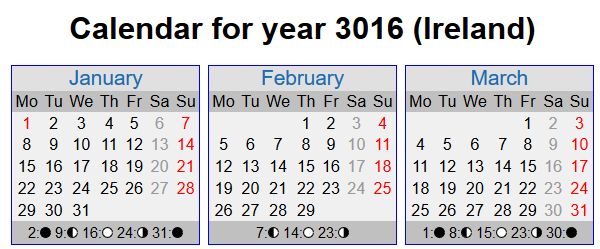
A crawler will never reach the end of these calendar pages unless a system is in place to manage a reasonable cut-off date, which of course will need to be revisited once that date becomes reasonable in future!
There are a number of relatively straight-forward fixes to ensure this is never an issue for your site. Using a ‘noindex, nofollow’ meta tag on ‘beyond reasonable date’ years is one option, whilst employing the robots.txt file to disallow any date-specific URLs beyond a certain timeframe is another option, although this route is uncommon.
Most out-of-the-box Web 2.0 calendar plugins and self-build functionality guidelines come pre-built with these crawling considerations in mind, but it does crop up now and again for some older sites with tonnes of other legacy issues, there’s a handy host constraint solution for calendar traps outlined in the JIRA archives should the need arise.
A never-ending URL trap can be found on pretty much any website and does not share common traits across industry sectors nor transactional-versus-non-transactional domains; it is usually just the product of a malformed relative URL or poorly-implemented server-side URL rewrite rules.
It’s very uncommon to see the results of this particular trap within a web browser or indeed within the SERPs as they’re often buried deep within a site’s IA and can often be the very reason why some content beyond the point of a never-ending URL is not actually indexed for a user to find. These generally only become evident with the use of a crawl tool such as the excellent Screaming Frog or Xenu Link Sleuth.
You can tell something’s up when you start to notice that a) the crawl is hitting a stumbling block and looping back on itself, as per above and b) some really funky-looking URLs start cropping up in the crawl dashboard with tens, hundreds, even thousands of crazy-looking directories appended to it. Here’s an example of a recent case of this exact trap encountered on an ecommerce client’s site:
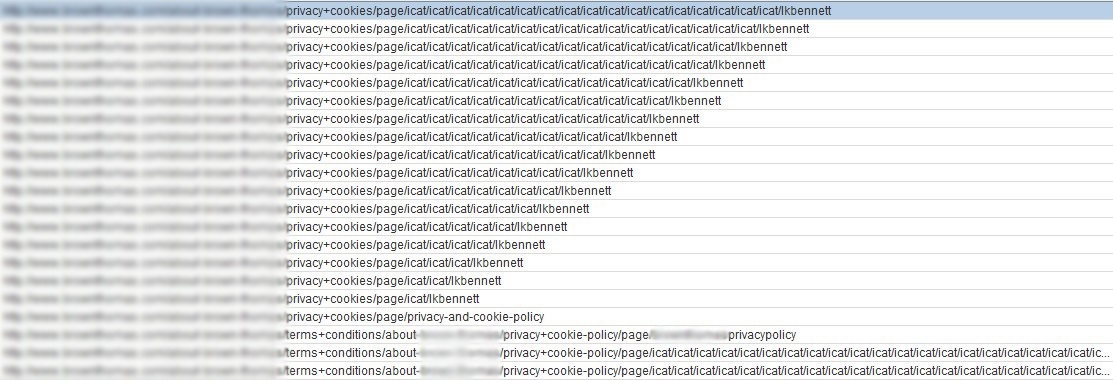
Note the lack of a proceeding slash on the relative link, enough to fool the spider into thinking there are an infinite number of directories proceeding this directory, thus sending the crawl into overdrive on an infinite URL loop!
This is just one of the many reasons we’re not fans of relative links here at Wolfgang, absolute URLs are the order of the day, but that’s a whole other topic for a different day! Yoast’s Joost de Valk has a detailed blogpost expressing the rather extreme view that relative URLs should be forbidden for web developers, citing spider traps as one of the key risks associated with their use, while Ruth Burr-Ready has an excellent Whiteboard Friday session covering why relative URLs can be an SEO’s worst nightmare; well worth a watch to help develop a further understanding of this topic as a whole.
Relative linking issues aside, some other reasons you might find an infinite URL string cropping up in a crawl environment include poorly configured URL rewrite rules from a previous website migration project or malformed query parameters which ignore large sections of a URL string due to of server-side dynamic URL serving, e.g. if someone types ‘www.yoursite.com/this-is-a-completely-made-up-url’ but server still returns a 200 response code within a crawl instead of a 404. The solution for this remains pretty much the same across the board; the need for a properly maintained URL management infrastructure in conjunction with correct server response code handling.
Once you’ve noticed this kind of trap occurring, you can use the sort functionality within the crawler tool to sort by URL length; find the longest URL and you’ll then find the root source of the issue, in the above case we were able to isolate the culprit as residing somewhere within the source code of the ‘lkbennett’ directory.
It’s then a matter of sifting through the source code of the page in question and looking for anomalies. It turns out that at the very root of this spider issue, lay a very simple mistake; a tiny typo on line 2354 of the code within a relative URL link configuration:

Considering there are over 1300 links on the page in question and any one of these could have potentially been the cause, it was a proverbial needle in a stack of needles, but an experienced eye can spot these issues fairly quickly. Big relief that it wasn't a much, much worse issue; once flagged, this was put to bed in a matter of minutes and the site was back firing on all cylinders in no time!
Failing a manual weeding process, there are some more technical ways of addressing the situation, either by disallowing the offending parameters with the robots.txt file or by adding server-side rules to ensure that URL strings with a certain maximum limitation of URL strings on them. Both of these approaches require some savvy programming skills but the net aim is for non-existent URLs to correctly serve 404 response codes rather than allowing them to be pawned off as 200 (OK) pages for infinite bot consumption.
If you’re fortunate enough to have access to a dev team with the skills to implement these workarounds, they should also be well-equipped to build a more permanent resolution to the issue which led us here in the first place; namely in the form of a rebuild or fully-functional URL rewrite exercise.
A session ID spider trap is generally found on larger ecommerce websites where the need has been established for more granular user session tracking, channel attribution and cross-sell between established SBUs without the desire for over-reliance on cookies as the primary data collection instrument.
This kind of trap can usually be picked up pretty quickly by crawling your website and looking at the list of crawled URLs for something like this:

Commonly-identified symptoms of the Session ID trap are the appearance of tags like ‘jsessionid’, ‘sid’, 'affid' or similar within the URLs strings as a crawl unfolds, with the same IDs re-occuring beyond a point where the spider can successfully move on the the next ID-laden URL string.
Other times, as established sites test new ways of user and cookie tracking methods (without prior knowledge of how this might impact crawl efficiency), the potential for a likely spider trap issue can be identified almost instantaneously within the browser if a constant parameter string is appended to the previously-normal-looking TLD:

In each of these very different cases, the use of ‘jsessionid’ and ‘opt=’ are attempts to track user sessions without the use of a traditional, cookie-based attribution model, not something we’ve ever overly-keen to recommend as the propensity for error is so high; we’re yet to see it implemented without some major downsides.
The logic behind the implementation of session ID tracking is that if a particular URL visited by a user doesn’t a session ID associated with it, then a user is redirected to the same URL version with the session ID appended to the end of it, as per the above ‘opt=’ example. If the requested URL does have the requisite session ID attributed to it, then the server will load the relevant webpage but it also appends the session ID to each and every internal link on the same page; this is where it all starts to unravel from a spider’s perspective as there’s so much that can and often does go wrong at from here onwards that is enough for us to warrant a call for this practice to avoided in its entirety where possible!
The fact of the matter is, there’s almost always a couple of links that slip through the net here, that aren’t correctly attributed the specific session ID in order for this tracking project to function smoothly. If the structure contains just a single internal link without the relevant session ID due to incorrect implementation, then the link will effectively generate a brand new session ID each time it’s followed. This means that from a spider’s PoV, it arrives at a new version of the entire website being tacked under a brand new session ID each time this rogue link is accessed. Confused yet? Imagine what the poor spider makes of it all!
To diagnose this kind of issue during an initial site crawl, it may be necessary to first exclude the offending parameters within the crawl tool itself so that the crawl can successfully be completed. More and more problematic parameters can be picked up as exclusions are added, until crawl completion is finally possible. This can look something like this for the above example to exclude the problematic ‘opt=’, ‘so=’ and ‘returnurl’ rule parameters from the Screaming Frog crawl:
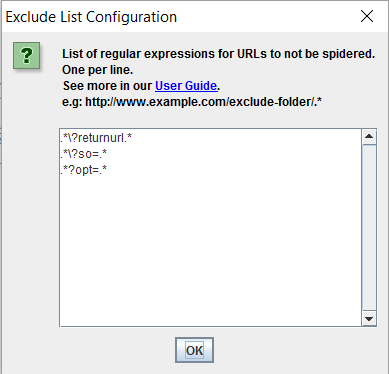
The ideal solution here is that this logic be removed from the site entirely, but if a band-aid solution is required, then replicating these exclusions within the robots.txt file should ensure that Googlebot and other search engine spiders can now get beyond the trap and start indexing some of the more important URLs we want the site to have organic visibility for.
Managing URL parameters within Google Search Console can also help with the task of instructing Googlebot on specific ways to deal with specific parameters, with the options to crawl, don’t crawl, or ‘let Googlebot decide’ using active/passive rules within the dropdown boxes available beside each parameter instance.
However, as you’ll notice when you log in to this area of GSC, a prominent warning of ‘Use this feature only if you're sure how parameters work. Incorrectly excluding URLs could result in many pages disappearing from search’ welcomes Webmasters upon arrival:
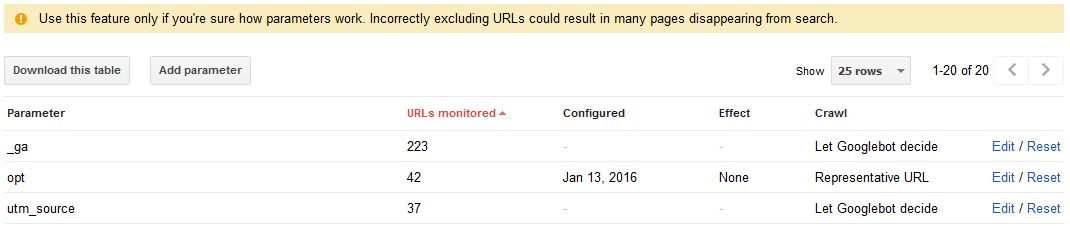
Handle with care on this one, as it’s probably one of the most advanced sections within the entire Google webmaster suite. Be sure to read up on the official guidelines on the topic if this is a rabbit-hole you’re keen to explore the depths of.
If your site is falling victim to this issue, the only sure-fire way to fully address this kind of spider trap is to completely remove every single instance of session IDs from all hyperlinks and all internal redirect rules across the entire site. Care must be taken to ensure that every instance is removed as if even one instance remains, the crawl will still throw up a potentially unlimited number URLs as it reaches the point of error within the IA.
This particular spider trap is the one we’ve found the most challenging to address here at Wolfgang HQ, not only as the solution is often hard to implement but because, in theory, faceted navigation is one of the greatest UX features on any modern ecommerce website; it allows users to filter deep within a site’s menu structure to find what they really want, fast.
As highlighted by Clickz in this great take on how to make robots cry with faceted navigation, its presence on a site ‘is an almost-universally positive experience for humans.’
Two of the most important benefits of faceted navigation are outlined as:
The problem is, when there’s a massive list of items on a site, and they can all be sorted by a large number of filtering options, then the potential for all sorts of bizarre URL permutations is quite staggering if not managed correctly from the outset.
If your website offers users a range of different products with many different ways to navigate towards finding these items, it may well be susceptible to this kind of spider trap.
Looking for elongated URL strings, various reoccurring filtering tags and a never-ending loop within a crawler tool is again the tell-tale indicator of whether your site is configured to handle faceted navigation in an SEO-friendly manner or not.
Common sorting labels such as colour, size, price, or number of products per page are just some of the many filter tags that can create issues for a crawler upon visiting your site. Crawl issues around faceted navigation generally start to arise when it becomes evident to a spider that it is possible to mix, match and/or combine various filter types.
For example, using the case of a hugely popular Irish DIY store below, if a user is looking to purchase some paint for an upcoming home decoration project, then it’s useful that he or she can navigate through to desired options using filter items such as colour, brand and price.
The issue arises when the same user can then also sort this filtered result by number of products per page, the category of paint that it is, a maximum price rand, a minimum price range and so on and so forth. It should be able to filter by a couple of different, important filters, but not by all, simultaneously.
During the initial phases of our technical auditing process on this website, our crawler was set to emulate Googlebot using the excellent ‘user-agent’ settings in Screaming Frog.
Iit quickly became apparent that a spider trap was being experienced meaning that the spider was essentially being sent on an infinite, never-ending loop through a series of filters as a result of the faceted navigation structure of the site, resulting in long URL strings such as ‘www.website.ie/kitchen-and-bathroom/kitchen?FilterCategoryID=8399&BrandID=3455&Page=1&PriceHigh=2147483647&PriceLow=0&SortBy=1&q=&ProductsPerPage=9’ being churned out, only to be sent through yet another iteration of the filtering process, leaving our crawl running for days on end without ever reaching completion.
We knew it was a big site, but eyebrows began to raise with over 20,000,000 URLs crawled!
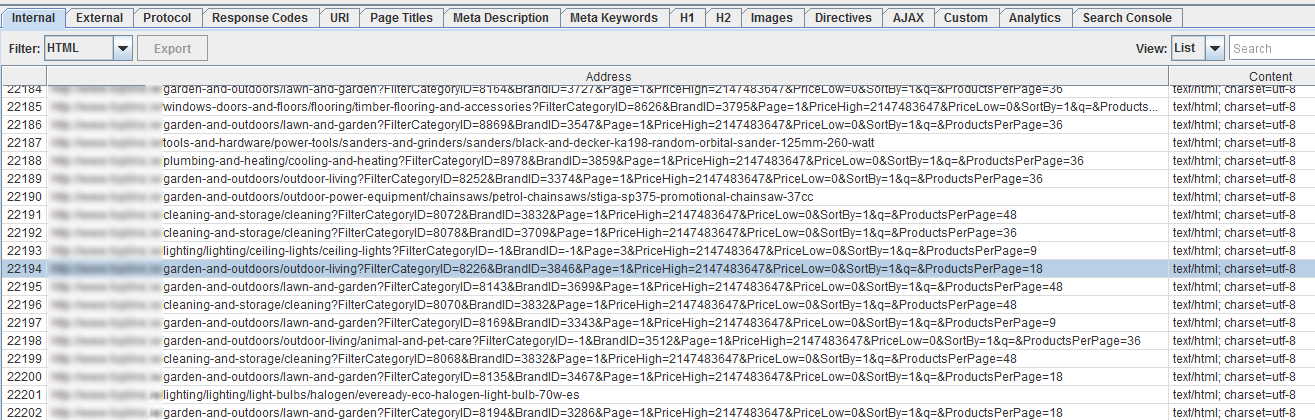
This scenario throws up a potentially endless, (well in the multiple billions, anyway!) number of permutations that a user can tweak to get their ultra-tailored result, which may ultimately just be a single, very long URL with a single product result displayed on its corresponding web page.
With the greatest UX intentions at heart, this faceted nav structure has failed to take the very fundamental SEO consideration into account; ‘how on earth does a search engine fetch, render, parse, index and rank these multiple billions of URLs?!’ (the answer is, it doesn’t, it gives up and moves on at some point, as covered in our crawl budget analogies, above!).
Again, applying exclusions to the crawl tool will be necessary just to complete the crawl in question.
In order for us to ensure we could exclude insignificant filters, without negatively impacting the ability of important categories or brand listings, we first needed to understand which filters could be dropped from the crawl process, and which could remain, all the while testing to ensure that major landing pages, categories and product listings were not affected.
After a period of consultation with the client, we were unable to determine the filters pertaining to content that is important to rank for (brands and categories) and which ones are superfluous in the context of SEO (size, no. of products per page, maximum price, minimum price, etc.)
An exclusion of that sort looks like this within a site’s robots.txt file:
Disallow: /*PriceHigh.*
Disallow: /*PriceLow.*
Disallow: /*SortBy.*
Disallow: /*ProductsPerPage.*
Disallow: /*searchresults.*
Robust testing is required with each exclusion inserted; exclude too much and some important listings could be blitzed from the SERPs, exclude too little and the problem may only be partially addressed.
It’s important to be aware that the net result of this exclusion process will ultimately mean that there will be less pages indexed in Google and other search engines, but that the remaining listings will relate to the more important pages on the site, that duplication will be reduced and, most importantly, that the spiders will be better positioned to have the opportunity to crawl the entire site and re-prioritise it’s understanding of the site, free from the risk of a spider trap. It should result in a win-win situation for both spiders and webmasters (and subsequently, business owners).
The best form of defence against this kind of issue borne of faceted nav is to avoid it to begin with! In the above case, applying the recommended exclusions and rebuilding the site’s mega menu in HTML5 in place of a JavaScript menu helped tame this particular spider trap and the site is reaping the rewards from an organic traffic perspective.
That’s not to say that JS menus can’t prove effective, but they need to be set in a way that doesn’t allow for multi-faceted layers to populate within dynamic URL strings. More is not always best, giving users choice is always a good thing, but there comes a point where logic needs to prevail and for a user case to be built around the pros and cons of having another four or five filter objects that won’t really influence purchase at the end of the day.
When using JavaScript to serve faceted navigation, it's important to decide on how and what to serve the spiders and in which format. Rather than just serving unreadable JS tags, we recommend using a pre-rendering mechanism such as Prerender.io in order to make the transitions through to JS as smooth as possible for the predonimently HTML-savvy spiders.
If exclusions and/or rebuilds aren’t feasible options, then adding canonical tags to offending URL strings can certainly help with the indexation side of things and will help avoid thin content and potential site penalisation at the hands of Google Panda, but it does not address the fact that these awful, elongated URLs first need to be crawled in order for the canonical directive to be picked up and respected by the spiders.
Now that you’ve gained a deeper understanding of the potential cause of and solution to these four main common spider traps, we hope you can begin to appreciate the importance of embracing the spiders for enhanced overall performance of your website from an SEO perspective.
There’s also another pretty interesting instance of spider traps arising from keyword search indexing that’s worth investigating if none of the above spider trap issues are the root of your crawling woes. We’ve yet to encounter this issue on any of our clients’ sites, hence the lack of detailed coverage; fingers crossed that remains the case for some time to come!
If you’ve conducted any of the changes suggested above to remedy your spidering woes, we’d highly recommend you use both Google Search Console and Bing Webmaster Tools to resubmit your XML sitemaps and allow them to render and index with the new changes in place, you’ll be amazed at how your estimated crawl budget tends to rise within a couple of months of the spiders have a better grasp of a website in a post-trap environment! Using Google’s Fetch and Render option on the fly as site changes are made is a sure-fire way to test success rates and ensure all is well from a crawl perspective.
Ensuring that internal linking is well utilised throughout your site and that you’re creating fresh content are two sure-fire ways to ensure that Googlebot understand which areas of your site are the most important to you in this fresh new, spider-friendly IA you’ve enabled. Continual reminders through smart use of content, links and sitemaps will help ensure topic priority is sculpted accordingly.
Finally, we’d recommend embedding a process whereby you’ve got a clearly-defined schedule for periodic SEO crawling mapped out for your site. As illustrated in detail above, there’s a lot of moving parts when it comes to URL management and indexing, so it makes sense to run a crawl every couple of days, weeks or months, depending on the size of the site and the frequency of change it undergoes. If you're an existing Wolfgang client, you can rest safe in the knowledge that we're on the case if your site does ever experience the wrath of a spider trap, but if any of our readers are keen on learning more about our SEO methodologies, you can always contact us and we'll gladly crawl your site for you!
Do you have any crazy crawl issues to report or have you seen an instance of a spider trap on your own site or a site you manage? If so, please don’t be a stranger in the comments box below or indeed on social; we’d love to hear your feedback or answer any queries you may have in relation to taming the spiders on your domain!


Partner with a 6x Best Global Agency Winner that's as invested in your growth as you are.









